
At the time of writing, the hunt is still on for Malaysia Airlines flight MH370. Bayesian search theory has become topical (again). Bayesian search has been used to find crashed planes, lost hikers, sunken submarines and even missing hydrogen bombs. Bayes' theorem is perfectly suited to search because it provides a mathematical framework for deductive reasoning. Let's try it out.
Here's our (semi-fictionalised) search scenario: In 217BC, Rome and Carthage are at war. Dido's curse still haunts the two civilisations. Carthaginian General Hannibal Barca has just annihilated a Roman army at Lake Tresimene, 180km northwest of Rome. He had already inflicted a series of crushing defeats on the Romans to the point that, after Lake Tresimene, Rome was left virtually without any field army at all. The great fear was that Hannibal would now march his war elephants on the city of Rome itself. In times of dire emergency, the Roman republic allowed for the temporary appointment of a dictator. Five days after Lake Tresimene, the senate appointed Quintus Fabius Maximus as dictator. The first question for him was: where is Hannibal now?
We're going to do a Bayesian search for Hannibal's army. Before we can start, the first thing we need to do is construct a probability map of where Hannibal could be. In Bayesian parlance, the prior.
Constructing the prior search space
Let's start with a map of Italy:
# prepare iPython
%pylab inline
import numpy as np
from numpy import vectorize
import pandas as pd
import scipy
from scipy import spatial
from scipy.stats import beta
from mpl_toolkits.mplot3d import Axes3D
from mpl_toolkits.basemap import Basemap, shiftgrid, cm
# locations in lat, long
Rome = [41.9, 12.5]
Trasimene = [43.133333, 12.1]
# plot Italy
fig = plt.figure(figsize(6,6))
m = Basemap(width=900000, height=900000, projection='lcc',
resolution='h', lat_0=Rome[0], lon_0=Rome[1], area_thresh = 1000)
## plot topography
m.shadedrelief()
m.drawcoastlines()
m.drawrivers()

et's zoom in on the part of Italy where the action takes place:
m = Basemap(width=300000, height=300000, projection='lcc',
resolution='i', lat_0=Trasimene[0], lon_0=Trasimene[1], area_thresh = 1000)
# convert locations to X,Y co-ords for plotting
RomeXY = m(Rome[1],Rome[0])
TrasimeneXY = m(Trasimene[1],Trasimene[0])
def plot_italy():
fig = plt.figure(figsize(6,6))
## plot topography
m.shadedrelief()
m.drawcoastlines()
m.drawrivers()
# plot location of Rome
m.plot(RomeXY[0], RomeXY[1], 's', markersize=12, c='red')
plt.text(RomeXY[0]-10000, RomeXY[1]+10000,'Rome',size=9)
# plot location of Lake Trasimene
m.plot(TrasimeneXY[0],TrasimeneXY[1], 'bo', markersize=12)
plt.text(TrasimeneXY[0]-13000, TrasimeneXY[1]+10000,'Lake T.',size=9)
plot_italy()

The topography is a little blurry when you zoom in on matplotlib's basemaps (sorry about that). The important thing is that we can see the mountains and that's material to our search. We're going to focus on this 300x300km part of Italy, with Lake Tresimene in the middle and Rome to the south. Incidentally, matplotlib's basemap() function returns an (x,y) grid, where x & y are measured in meters. So my plot is a 300000x300000 grid.
Now we want to calculate P(Hannibal=present) for each (x,y) $\text{km}^2$ in our search space. Where could Hannibal be? Anywhere in Italy? If we thought Hannibal could be literally anywhere in Italy with equal probability then we would have a very large search space and no idea where to start. But Fabius Maximus knows a few things that will narrow the search space:

Fabius Maximus
- Hannibal can't be more than five-days' march from Lake Tresimene
- He is more likely to have headed south than north (he came from the north)
- He is going to be on land
- He is less likely to be found in mountainous regions, since elephants are notoriously difficult to lead uphill (note: prior to Hannibal's arrival, most Romans had never seen an elephant, so misinformation was rife).
Our first job is to code these four beliefs into a prior probability distribution over our search space. One of the challenges of the Bayesian approach is that everything must be mathematically quantified, and sometimes this takes guesswork or approximation.
Let's start with the first two: Hannibal can't be more than five days' march from Lake Tresimene. Fabius Maximus does some mental calculations, makes allowances for war elephants... and decides that Hannibal could march his army up to 20km per day. For the full five days, let's assume that the distance he could march can be represented with a beta distribution shaped like this:
rv = scipy.stats.beta(4, 2, loc=0, scale=100000)
marchDist = np.linspace(0, 100000, 50)
pmarchDist = rv.pdf(marchDist)
fig = plt.figure(figsize(6,3))
plt.plot(marchDist, pmarchDist)
plt.title("PDF for five days' march")
plt.xlabel("Distance travelled (m)")

Fabius Maximus has no idea which direction Hannibal went, but he expects that Hannibal is unlikely to head back north. So let's assume any direction that is south of Lake Tresimene is twice as likely as those to the north. Thus we'd therefore expect to find Hannibal in donut-shaped probability distribution centered around Lake Tresimene, with the bottom part of the donut having a higher probability than the top half:
# construct a 300x300 grid for our probability distribution
Xrange = np.linspace(0, 300000, 300)
Yrange = np.linspace(0, 300000, 300)
XX, YY = np.meshgrid(Xrange, Yrange)
XYgrid = np.c_[XX.ravel(), YY.ravel()]
zdist = spatial.distance.cdist(XYgrid, [TrasimeneXY])
p_march = rv.pdf(zdist).reshape(XX.shape)
# Double likelihoods for all points south of Lake Tresimene
# --> Create matrix where all points with y-dimension < Lake Tresimene Y-coord are 2, the remainder are 1
p_southwards = map(lambda x: 2 if x[1] < TrasimeneXY[1] else 1, XYgrid)
p_southwards = np.array(p_southwards).reshape(XX.shape)
# combine the two beliefs into a single search space
p_prior = exp ( log(p_march) + log(p_southwards) )
# Normalise into a pobability distribution that sums to 1
p_prior = p_prior / sum(p_prior)
# define colourmap for probability contours
my_cmap = matplotlib.cm.get_cmap('RdYlGn')
## Plot
# mask zeroes so that matplotlib colourmap ignores them
p_prior_plot = p_prior.copy()
p_prior_plot[p_prior_plot==0] = np.nan
plot_italy()
m.contourf(XX, YY, p_prior_plot, cmap=my_cmap, alpha=0.5)
plt.title("P(Hannibal) probability map")
cbar = m.colorbar()
cbar.ax.get_yaxis().set_ticks([])
cbar.ax.text(1.1, 0.93, 'Higher\nprobability', ha='left')
cbar.ax.text(1.1, 0.01, 'Lower\nprobability', ha='left')

Already we've cut down the search space dramatically. We can do better: let's add in beliefs three & four. Fabius Maximus knows that it would be difficult for Hannibal to lead his army into the mountains. He guesstimates that Hannibal is far less likely to be in higher altitude regions than in the plains. Using topological data we can reduce the probability of the mountainous regions of our map:
## extract topological data for our region
# get topological data
from netCDF4 import Dataset
url = 'http://ferret.pmel.noaa.gov/thredds/dodsC/data/PMEL/etopo5.nc'
etopodata = Dataset(url)
topoin = etopodata.variables['ROSE'][:]
lons = etopodata.variables['ETOPO05_X'][:]
lats = etopodata.variables['ETOPO05_Y'][:]
# shift data so lons go from -180 to 180 instead of 20 to 380.
from mpl_toolkits.basemap import Basemap, shiftgrid, cm
topoin,lons = shiftgrid(180.,topoin,lons,start=False)
# limit to our region, and transform to a 300x300 grid, same as our existing probability space
topodat = m.transform_scalar(topoin, lons, lats, 300, 300)
## define function that codes regions with relative likelihoods
def topoprobs(x):
if x < 0:
return 0.0 # below sea level = no chance
elif x <= 250:
return 0.6 # not mountains = most likely
else:
return 0.3 # mountains = half as likely
topoprobsvec = vectorize(topoprobs) # vectorise function
# convert topographical data into relative likelihoods
topodat2 = topoprobsvec(topodat)
## Combine existing probability map with topographical probabilities
p_prior = exp ( log(p_prior) + log(topodat2) )
p_prior = p_prior / sum(p_prior) # normalise
## Plot
# mask zeroes so that matplotlib colourmap ignores them
p_prior_plot = p_prior.copy()
p_prior_plot[p_prior_plot==0] = np.nan
plot_italy()
m.contourf(XX, YY, p_prior_plot, cmap=my_cmap, alpha=0.5)
plt.title("P(Hannibal) probability map")
cbar = m.colorbar()
cbar.ax.get_yaxis().set_ticks([])
cbar.ax.text(1.1, 0.93, 'Higher\nprobability', ha='left')
cbar.ax.text(1.1, 0.01, 'Lower\nprobability', ha='left')

So we have defined a probability distribution across our search space. There are a few strips of dark green which correspond with the low-lying areas roughly four- to five-days' march south of Lake Tresimene. This reflects Fabius Maximus' beliefs about where Hannibal probably is.
With more beliefs we could go on developing our search space, but we'll stop there. It may have struck some readers that our definition of the search space using the Roman beliefs was somewhat haphazard. Why, for example, did we define 'higher altitude' as 250m above sea level, rather than 500m? or 100m? Often, we must resort to guesswork or arbitrariness in order to quantify our beliefs. We'll talk a bit about that at the end.
Bayesian searching
The process of Bayesian searching works like this:
- Select a spot from your probability map - ideally, select the spot which has the highest probability of containing the target
- Search it
- If you find the target, stop. If you don't, then update your probability map to show that you've looked in that spot

Hannibal Barca
This is common sense. The beauty of the Bayesian method is that it a mathematical framework for commonsense, deductive reasoning.
If we search an area for Hannibal and he isn't there, then the math for updating our probability map looks like this:
P(Hannibal = present | chance of spotting him) $\propto$ P(chance of spotting him | Hannibal = present) * P(Hannibal = present)
We do that for the entire (x,y) grid. (Incidentally, the intuitive approach of treating the search space as a grid of discrete points, rather than a continuous space, makes the application of Bayes much simpler.) In practice, to avoid potential problems that can be caused by multiplying small numbers together, we use logs to do the calculation:
log[P(Hannibal = present | chance of spotting him)] $\propto$ log[P(chance of spotting him | Hannibal = present)] + log[P(Hannibal = present)]
We've already defined our map of P(Hannibal = present). Let's address the chance of spotting him:
- Assume that a Roman scouting party has a 99% chance of spotting Hannibal if Hannibal is in the same (x,y) $\text{km}^2$ spot. (Why not 100%? Well, let's just say that those Roman scouts aren't all reliable. Sometimes they get lost and go to the wrong spot, and sometimes they instead undertake a search of the local publican's house, etc.)
- A scouting party will search around their target area, and they can (of course) see farther than 1km. But their visibility rapidly diminishes, and their chances of spotting Hannibal get smaller as the distance from the target search area grows. We assume that their chances of spotting Hannibal decrease by 5% with each km.
This all makes more sense when you see it done, so let's try it.
Where should Quintus Fabius Maximus search first? We have a few places on the map with equally high probability. Fabius Maximus is particularly worried that Hannibal might be headed towards Rome, so he sends a scout out to look at that high-probablity spot on the Tiber river here:
plot_italy()
m.contourf(XX,YY, p_prior_plot, cmap=my_cmap, alpha=0.5)
scout1 = [165000, 80000]
m.plot(scout1[0],scout1[1], 'bo', markersize=12, c='yellow')
plt.text(scout1[0]-10000, scout1[1]+10000,'Scout',size=8)

On arriving, the scouting party looks around. Let's plot their field of vision or, in terms of our likelihood formula, P(chance of spotting him | Hannibal=present):
## plot scout field of vision
# Calculate distance of all points in our grid to scout
XYgrid = np.c_[XX.ravel(), YY.ravel()]
zdist = spatial.distance.cdist(XYgrid, [scout1])
# Calculate probability of scout spotting Hannibal, were he present, at each grid point
p_search = (0.99 * 0.98**(zdist/300)).reshape(XX.shape)
p_search = np.round(p_search, 3) # round off at 3 decimal places - beyond that the chance of spotting is so small...
## Plot
# mask low probabilities so that matplotlib colourmap ignores them
p_search_plot = p_search.copy()
p_search_plot[p_search_plot<0.05] = np.nan
plot_italy()
plt.text(scout1[0]-10000, scout1[1]+10000,'Scout',size=8)
scout_cmap = matplotlib.cm.get_cmap('Blues')
m.contourf(XX,YY, p_search_plot, cmap=scout_cmap, alpha=0.6)
plt.title("P(detection | Hannibal) map of scout's vision")

Darker shades of blue mean the scout is very likely to spot Hannibal (if he were there). Lighter colours, which are distant from the scout, mean that the scout could spot Hannibal there, but it's a long way away and it's less unlikely. Those distant spots we would be less confident about crossing off our map, as we have less confidence that they've been comprehensively searched.
This information about the likelihood of spotting is important. When we update our probability map, we want it to reflect that areas near the scout have been searched very well, and areas distant have been searched poorly.
Let's do that:
# use Bayes to update prior to posterior
p_posterior = exp( log(p_prior) + log((1 - p_search)))
p_posterior = p_posterior / sum(p_posterior) # normalise
## plot
# mask zeroes so that matplotlib colourmap ignores them
p_posterior_plot = p_posterior.copy()
p_posterior_plot[p_posterior_plot==0] = np.nan
plot_italy()
m.contourf(XX, YY, p_posterior_plot, cmap=my_cmap, alpha=0.5)
plt.title("P(Hannibal | chance of detection) after first search")
cbar = m.colorbar()
cbar.ax.get_yaxis().set_ticks([])
cbar.ax.text(1.1, 0.93, 'Higher\nprobability', ha='left')
cbar.ax.text(1.1, 0.01, 'Lower\nprobability', ha='left')

The spot on the river between Rome & Lake Tresimene has become red: the scout searched here and didn't find Hannibal, so it is unlikely (though not impossible) that he could be here. The area around that spot takes on receding shades of orange, yellow, and then green, reflecting the knowledge that scout's field of vision diminishes with distance.
The exact site of the scout's search now has a very low probability of concealing Hannibal though it is not zero. Nevertheless, we wouldn't search there again straight away, because there's a much higher probability of finding Hannibal in other places we haven't searched. Obviously, we should choose one of those places as our next candidate...
And that's how Bayesian search works. You just repeat that process, over and over, until you find the target. Because you always search in descending order of probability of finding Hannibal, you should find your target as quickly as possible.
Let's do one another round, this time with three scouts:
plot_italy()
m.contourf(XX, YY, p_posterior_plot, cmap=my_cmap, alpha=0.5)
plt.title("P(Hannibal) and scout's P(detection | Hannibal)")
# define locations for three scouts
scouts = [[300*250, 300*450], [300*300, 330*300], [390*300, 250*300]]
for scout in scouts:
zdist = spatial.distance.cdist(XYgrid, [scout])
# Calculate probability of scout spotting Hannibal, were he present, at each grid point
p_search = (0.99 * 0.98**(zdist/300)).reshape(XX.shape)
p_search = np.round(p_search, 3)
# update posterior
p_prior = p_posterior.copy()
p_posterior = exp( log(p_prior) + log((1 - p_search)))
p_posterior = p_posterior / sum(p_posterior) # normalise
## Plot field of vision
# mask zeroes so that matplotlib colourmap ignores them
p_search_plot = p_search.copy()
p_search_plot[p_search_plot<0.05] = np.nan
m.contourf(XX,YY, p_search_plot, cmap=scout_cmap, alpha=0.4)

## plot new posterior
# mask zeroes so that matplotlib colourmap ignores them
p_posterior_plot = p_posterior.copy()
p_posterior_plot[p_posterior_plot==0] = np.nan
plot_italy()
m.contourf(XX, YY, p_posterior_plot, cmap=my_cmap, alpha=0.5)
plt.title("P(Hannibal | chance of detection) after searches")
cbar = m.colorbar()
cbar.ax.get_yaxis().set_ticks([])
cbar.ax.text(1.1, 0.93, 'Higher\nprobability', ha='left')
cbar.ax.text(1.1, 0.01, 'Lower\nprobability', ha='left')

The important thing to notice here is that as the scouts have searched the high probability areas and turned up nothing, the areas which were low probability become relatively more likely to contain Hannibal. On the map, you can see this in the lightening green of the souhteast mountain range. Because Hannibal hasn't been found in lower lying areas, then it becomes more likely that he is in the mountains after all, defying our original beliefs. The beauty of the Bayesian approach is, again, that this logical reasoning is encoded in a simple mathematical framework.
Using Bayes' formula, we could even automate the process of logical, deductive searching if we wanted to. A computer would identify the most probable spot, search it, update the probability map, and repeat until the target is found. Indeed, this is precisely how it is often implemented in artificial intelligence systems (see discussion and examples in Norvig & Russell's Artifical Intelligence: A Modern Approach).
Let's try these. We'll do repeated iterations (up to one hundred) of automatic search, each time sending a scout to the spot with the highest probability:
# create 2x3 grid
fig = plt.figure(figsize(20,15)) # specifies the parameters of our graphs
nrows = 3
ncols = 3
gridsize = (nrows,ncols)
plotspots = [(i,j) for i in range(nrows) for j in range(ncols)]
counter = 0
scouts = [1, 2, 3, 4, 5, 6, 25, 50, 100]
for i in scouts:
while counter < i:
# set prior
p_prior = p_posterior.copy()
# identify highest probability spot
maxix = np.argmax(p_prior)
scout = np.multiply(1000, numpy.unravel_index(maxix, p_prior.shape, order='F'))
# Calculate scout vision - ie P(chance of spotting | Hannibal = present)
zdist = spatial.distance.cdist(XYgrid, [scout])
# Calculate probability of scout spotting Hannibal, were he present, at each grid point
p_search = (0.99 * 0.98**(zdist/300)).reshape(XX.shape)
p_search = np.round(p_search, 3)
# update posterior
p_posterior = exp( log(p_prior) + log((1 - p_search)))
p_posterior = p_posterior / sum(p_posterior) # normalise
counter = counter + 1
## Plot
ax = plt.subplot2grid(gridsize,plotspots[scouts.index(i)])
# draw italy
m.shadedrelief()
m.drawcoastlines()
m.drawrivers()
## plot scout
ax.plot(scout[0], scout[1], 'bo', markersize=10, c='yellow', alpha=0.8)
## Plot posterior
p_posterior_plot = p_posterior.copy()
p_posterior_plot[p_posterior_plot==0] = np.nan
ax.contourf(XX, YY, p_posterior_plot, cmap=my_cmap, alpha=0.5)
ax.set_title('Scout ' + str(i+5))
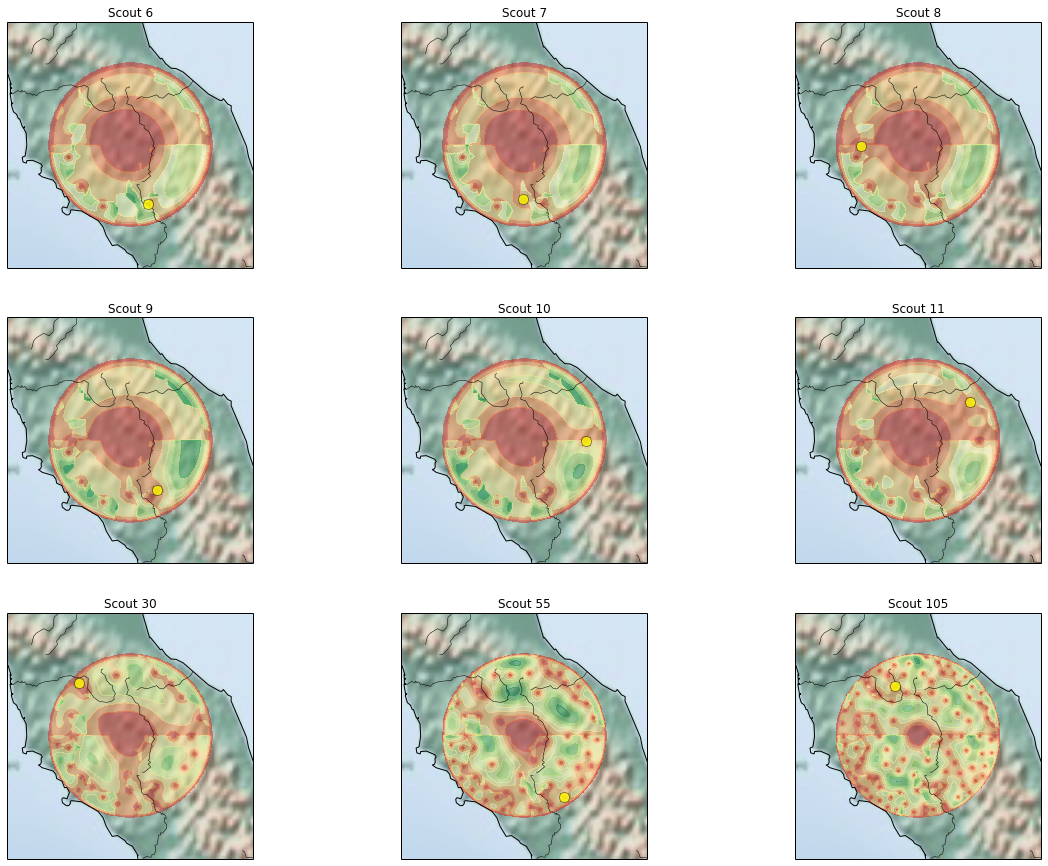
Closing notes
Of course, the Romans never did get Hannibal in Italy. After Lake Tresimene they stopped trying. Fabius Maximus' strategy was to avoid Hannibal's much-larger army and instead harass his supply lines. After 11 years of Hannibal marauding around Italy, the Romans had the idea to ignore him and attack Carthage instead. It worked: Hannibal was immediately recalled to defend his homeland.
Let's close by recognising the biggest shortcoming of the Bayesian approach. Bayes is a mathematical formulation for reasoning, which means it can only function if we can quantify everything. Any hypothesis or belief or evidence that we want to compute with Bayes must take a probabilistic form. This is a problem when we have information that isn't easily quantified. For example, we assumed that when a scout searches an area, he has a 99% chance of spotting Hannibal. Why 99% and not 98% or 53%? Well, it was 99% because that was my best guess. In order to get everything quantified so we can use Bayes, we may be forced to use guesstimation.
An obvious place where our guesstimations could be hugely problematic is in setting out the initial prior search space. If we choose our search space poorly by, for example, making the region too small, then the Bayesian search may go forever without finding the object. In our example, Quintus Fabius Maximus decided that Hannibal could not march more than 100km in fice days. But if Hannibal had marched more than that, then he would already have left the search space. This brings to mind Sherlock Holmes' dictum, “Once you eliminate the impossible, whatever remains, no matter how improbable, must be the truth.” In Bayesian searching, anything that we define as impossible in our prior - by which I mean we set the probability to 0 - will never become possible as it will never enter the search space.